

"Difference between optimization and learning in EA" (1/12) Investment AI development struggle diary
In 2022, optimizing with MT5 was trending
In 2023, the boom of optimization seems to have faded as over-optimization became a barrier
I am one of those who were inevitably knocked down by the wall of over-optimization
I believe EA has two parts: the logic part and the system part
There is a rule: do not optimize the logic part, but optimization is OK for the system part
The system is not about things like martingale multipliers or averaging down rules, it’s about the entry point
Well, strictly speaking... it can cause curve fitting, you know lol
Putting optimization aside for now,
these days I’m focusing on learning
Overview of the learning curve
Optimization and learning look similar at a glance, but there is a big difference
The following image shows a certain deep learning model’sloss curve(left) andaccuracy curve(right)
The loss curve has training (blue) and validation (orange) curves
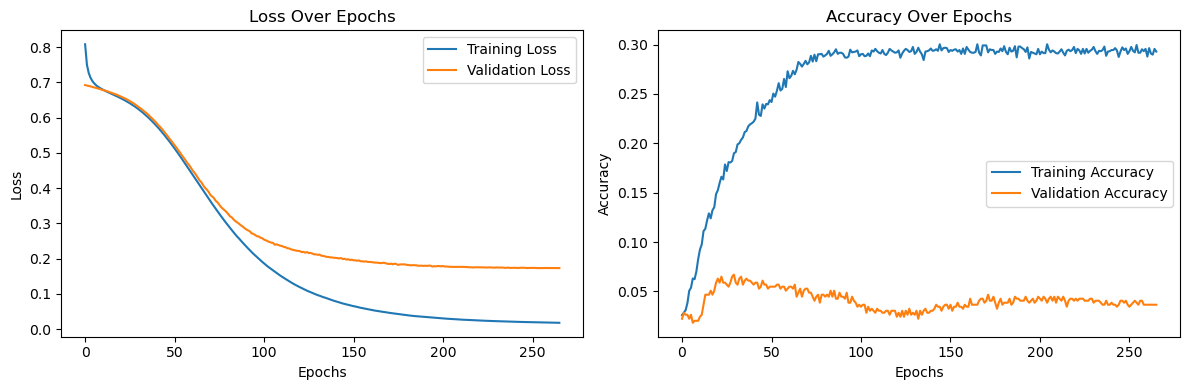
The vertical axis is loss (like points deducted in a test), and the horizontal axis is the number of learning iterations (like class sessions)
As learning iterations increase, loss decreases, but validation stops decreasing midway
No matter how many times you attend classes, you cannot get 100 points on the test
In EA, optimization is like training, and forward pass is like validation
The accuracy curve similarly has training (blue) and validation (orange) curves
Instead of loss being a score, accuracy feels like the probability of passing
Loss is quantitative, accuracy is qualitative
Similarities between optimization and learning
If you continue learning, loss can even increase
This is called overfitting
Similarly, if you fine-tune parameters too much during optimization, you may fail to fit future data
Therefore, besides the optimization period, a forward test section is prepared
If you overfit the forward test section, you start fitting to the forward test data instead
The concept of over-optimization and over-learning is shown below
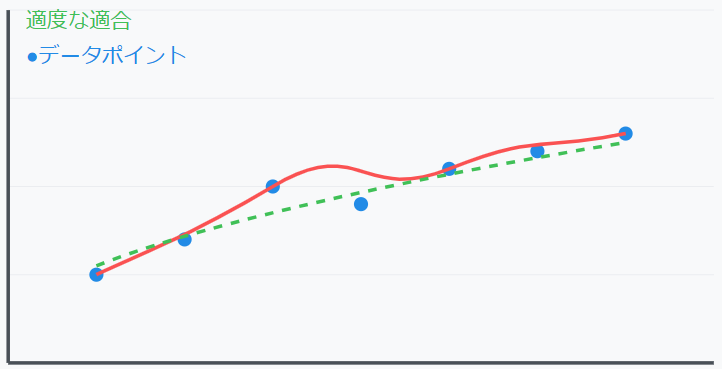
The plot carries noise; this is market noise
Noise means price movements that are not reproducible
By capturing this noise, you gradually deviate from the proper curve
It’s necessary to reduce the number of plots and create a moderately accurate curve
Differences between optimization and learning
From the above, optimization makes it hard to determine the actual curve location and evaluate it, but
learning can plot the loss curve and stop at an appropriate point
By avoiding improvement from noise, it becomes easier to handle unseen data
The ability to handle unseen data is called generalization performance
Often people talk about the EA expiration date, but if you can evaluate this generalization performance
you can lengthen the EA’s shelf life
Moreover, the more items to optimize, the more likely curve fitting becomes, but
in learning, more features allow learning finer market nuances
Concrete learning example
When creating a typical EA, indicators are usually about 10 types at most
Also, shifts of 1, 2, or 3 are common
Indicator 10 types × shift 3 = 30 items
Even at most this much, optimizing everything would quickly lead to over-optimization
Right now, I have about 300 types of indicators as features, and shifts from 1 to 200...
Using around 60,000 data points to predict the market
Collecting data is challenging
I aim to solve optimization challenges with machine learning while building a strong EA




